本文共 4366 字,大约阅读时间需要 14 分钟。
版权声明:本文为博主原创文章,未经博主允许不得转载。
BitTorrent协议。
BT全名为BitTorrent,是一个p2p软件,你在下载download的同时,也在为其他用户提供上传upload,因为大家是“互相帮助”,所以不会随着用户数的增加而降低下载速度。
下面是一般用ftp,http等分享流程:
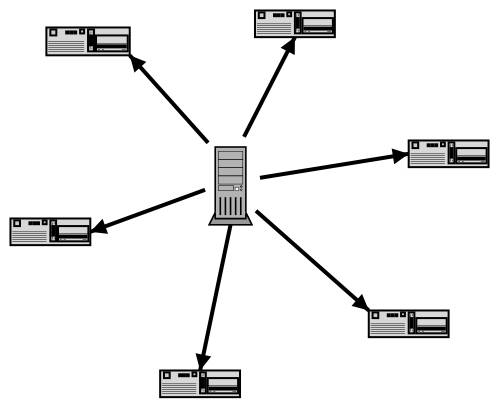
下面是用BitTorrent分享的流程:
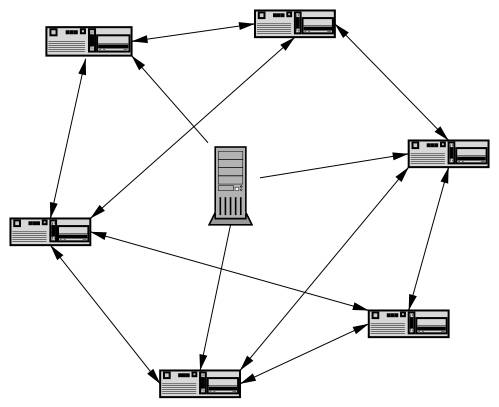
其实跟ED也十分相似,ED跟BT不同的地方有:
ED--要连上一个固定server BT--没有固定server,只要分享者制作出该分享档案的.torrent档公布出来便可
ED--分享的人越多速度越快? BT--种子seed越多速度越快
ED--世界性的分享 BT--团体性的分享(可做到速度保证)
ED--知道在分享者的user name &速度 BT--没显示使用者/分享者名字
比起其它的P2P软件,BT有个独特的地方,它存在一个中间的WEB服务器,就是我们在发布的时所填写的announce。 该服务器提供了发布的统一管理,不像其它P2P软件那样到处去找哪些非常不稳定的个人服务器,相对起来让人安心的多。
该WEB服务器更大的作用是内网用户可以做 Send(下面会说明原理),这是其它软件无法做到的,但不好的地方是announce当机的时候就无法下载了。要知道P2P下载关键是要人气要高,announce停一下就搞到人气全没有了。
.torrent 的作用
大家都知道我们要用BT下载 ,就要先下载一个.torrent文件,这个文件到底有甚么呢:
首先是 announce 纪录了发布服务器的位置,让BT知道是那个WEB服务器发布的,然后是一些文件信息,文件名,目录名,长度等等,最后是片段长度,和片段的 Sha1 校验码,(BT为了事现续传和文件校验,就把文件分成若干个片段),大家可以用写字板打看torrent文件看看,就是知道个大概,后面的乱码是片段 Sha1 校验码。
开始-续传的实现 sha校验
BT 打开一个 torrent文件后,先要你选择文件保存那里。然后判断文件不存在的话就建立新文件,存在的话就用 Sha1 校验码去校验文件---错误的就是还没下载的,这样就可以实现续传了,但128位校验,想不慢都不行
得到 peer
现在知道要下载甚么了,到那里下载呢?这就要寻找有谁提供上传了,这里BT是通过WEB服务器来实现的,首先BT会通过分析 torrent 来得到下面一串网址
http://btfans.3322.org:6969/announce?info_hash=%CDg%D4%19%AD%96%9D%93%03%DB%E4%FFXA%C6%5D%043%17O&peer_id=%00%00%00%00%00%00%00%00%00%00%00%00%A3E%E0%9BeB%90d&port=6882&uploadED=0&downloadED=0&left=19171922&event=startED
http://BTfans.3322.org:6969/announce 是发布服务器的地址
info_hash 是torrent文件中的 info 部分的Sha校验码,WEB通过它在发布列表找到对应的纪录
peer_id 是自身的标识,它是12个0和当前时间+全球的唯一标识码(GUID)的Sha校验的前八位,共20位
port 你提供上传的 port
IP 你的ip地址,没有的话服务器会自己找到
uploadED downloadED 你上传和下载了多少,服务器可以用它来做流量分析
left 你还要下载多少个字节
event 状态,告诉服务器你是准备开始下载,还是停止,还是下载完成了
以上这个操作默认 5 分钟做一次,或由服务器设定
服务器会做甚么
服务器中有个一个 track 程序来管理这些请求,得到这一串代码后就会用 info_hash 来查找列表,找到你就可以下载,找不到就对不起啦。接着它会反连(NatCheck)你的 IP 和 Port这样就可以知道你是内网用户还是共网用户(如果你是内网用户,它是连不通的,因为它会连到你的服务器上,你的服务器当然没有这个端口啦),然后服务器返回现在正在下载这个文件的所有公网用户的IP和port,就像是:d8:intervali1800e5eersld2:ip14:xxx.xxx.xx.xxx7eerid20:00180531904b7e3abdd74orti6881eeee
interval 1800 是告诉 BT 隔多少秒来查询一次这里是 30 分钟 (有点过分了),最后如果你是公网用户它会把你提交的 IP 和 Port 放到info_hash 对应的列表中,这样其它人就可以找到你
下载
得到这些 peer IP后,BT就可以找到对应的IP下载了,BT会到所有的peer去寻找自己要下载的东西,不是一定要到seed下载。BT每找到一个peer就和建立一个Socket来下载,所以下载的人越多,速度就越快。
内网用户可以做Send的原理
上面说到服务器只会返回公网的ip的,那内网用户怎么可以做Send呢,这是因为BT是一个主动连接的软件(即使你已经下载完了,也不也会主动连接他人)下面是一个仿真流程:
1 内网用户开始做 seed,
2 服务器收到请求,由于是第一个所以也没有peer返回
3 公网用户提交请求,由于seed是内网用户所以也没有peer返回,等待下载,但服务器会把它的IP放到列表中
4 内网经过 interval 时间间隔后,再向服务器放出请求,得到上面得公网IP
5 得到公网IP后,内网马上进行连接
6 公网用户建立连接,数据开始传输 (注意现在是公网用户做服务器,内网用户做客户端,是不是有点怪)
7 其它内网用户去上面公网用户下载数据
所以,内网用户做 seed 一定要有公网用户得参与,否则其它内网用户无法下载。如果全部是内网用户,那个所有连接都不会成立,当然这是比较极端的情况。
以上可见,内网用户不能和内网用户连接,其它用户无法从服务器查到你,所以无法主动连接你,你只能每隔30分钟从服务器找到公网用户一个个进行连接。
由于中国很多用户的是内网用户(我从服务器上查回来的peer还没试过超过10个的),所以内网用户用BT的确要比公网用户要慢很多